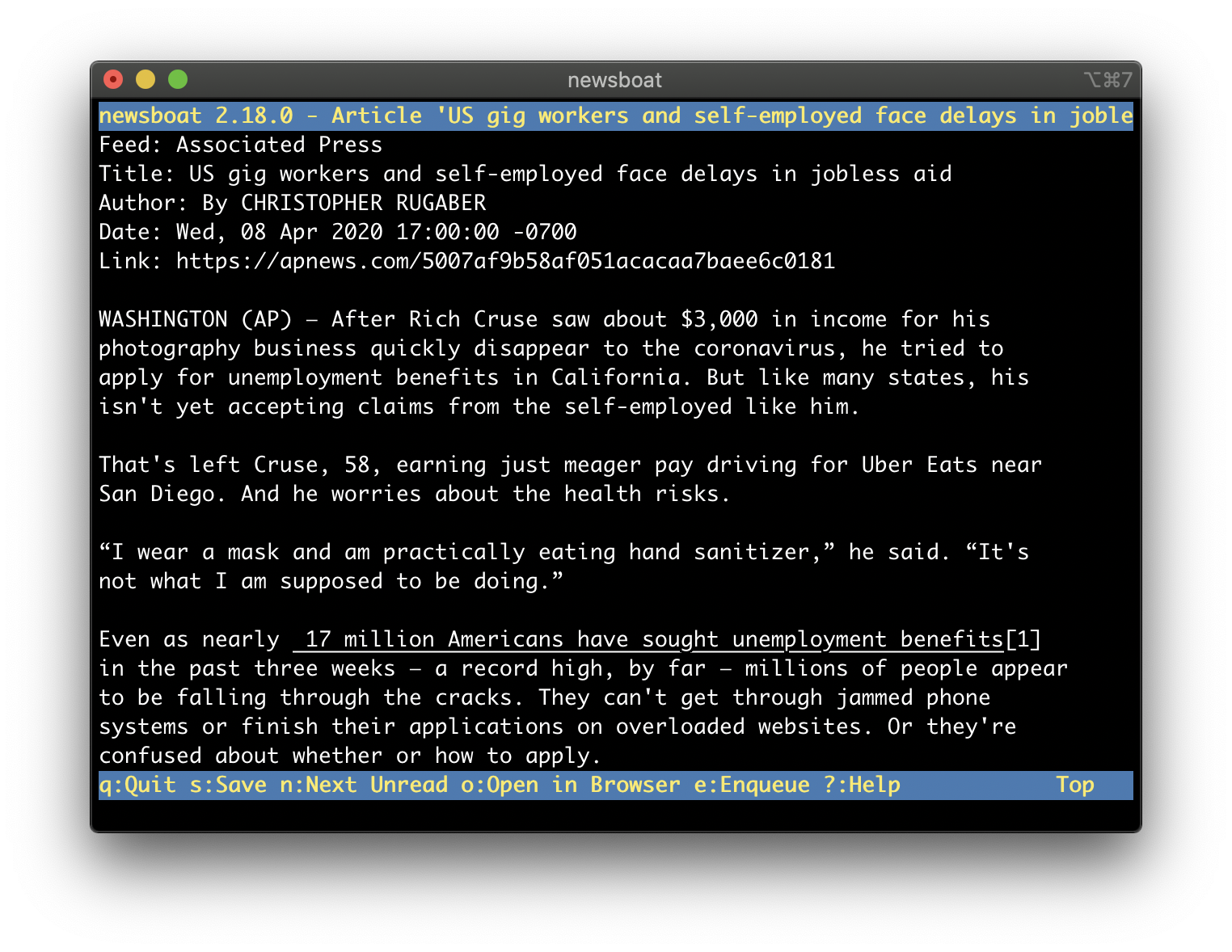
This was originally posted on my old blog. You can find the original source code here.
Modern news sites are garbage. They're filled to the brim with distracting advertisements, anti-ad blocker scripts, paywalls, auto play videos with sound, and "related content" bullshit. It's gotten to the point that browsing said websites have become an unpleasant experience (especially on low powered mobile devices). When I'm reading something on the internet, I want a distraction free experience. I don't want constant nuances to distract me from the content I'm trying to consume. So, to provide a distraction free way of reading the news, I wrote a spring boot application that fetches the news, and sends it to me in an rss feed.
Now before I get into the Spring Boot part of this story, let me take you back in time and explain the events that led me to this solution. Around 2018, I was trying to find minimal ways to read the news. As you can expect, not many news sites provide resources for terminal based browsing. The only news source that I could find that still supported text only browsers was NPR, and even that site only featured limited articles.
Around that same time, I also discovered a terminal application called newsboat, a small application designed for reading rss feeds in a terminal. This application was exactly what I was looking for, an application that would let me subscribe to my favorite news sites and read the news from the terminal. The only issue though was at that time, many modern news sites had moved away from providing rss feeds, and those that still provided an rss feed only offered limited features. For example, CNN's rss feed only contained the headlines, and a link to the full article.
I knew that if I wanted to have things my way that I would need to make my own RSS feed with the full article. So, around early 2018 I started work on a python script that would scrape the HTML elements from a site and generate an RSS feed file that newsboat can read.
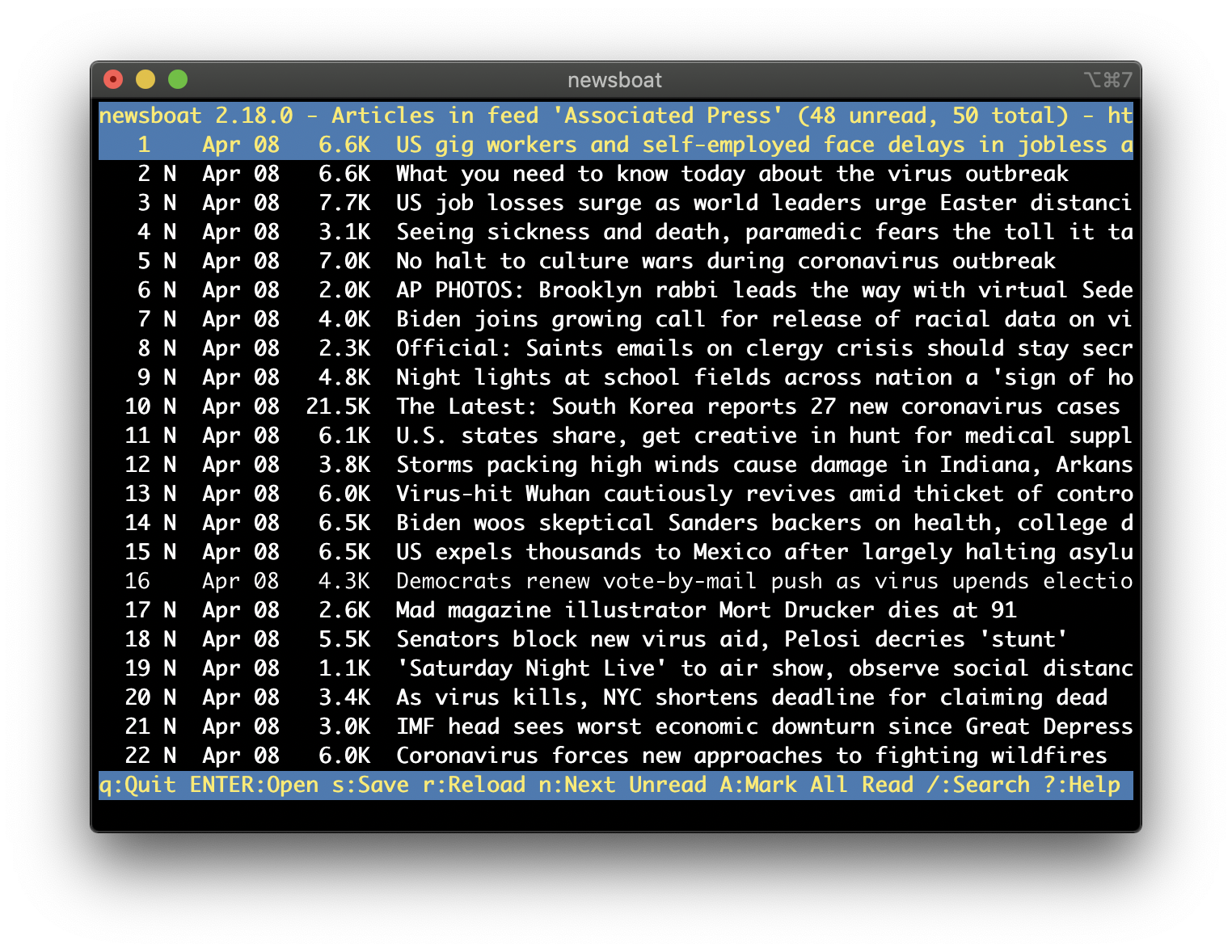
While the script got the work done, it had a few issues. The first one was that this script had to run every 30 minutes to update the local rss feed. This means that any news story that broke after the script ran would not be shown for another 30 minutes.
Another big issue was that if any HTML/CSS element was changed on the site I was scraping, the script would have to be changed to make sure the script could continue to parse the site correctly. The script also had little to no error handling, so if anything was off by one character, the script would stop executing, and the local rss feed would not be updated.
But the biggest disadvantage of the python script was that it relied on static HTML pages. Meaning that if the website text could not be loaded using curl, then the script would fail to run. This wasn't an issue when I started, but it became a bigger issue around early 2019 when the Associated Press (AP) changed their news site into a JavaScript web application. This became an issue since curl doesn't have support for JavaScript yet, and therefore could not run the scripts requiered to genorate the HTML text that the script needed to parse. After the AP site changed, I shelved this project until I could find a better way to scrape news sites with JavaScript.
Fast forward a few months later, I was interning at CDK Global, learning more about web development, learning about GET/POST request, and learning about debugging errors in web applications. After learning about the network tab under the dev tools in Firefox, I decided to goto multiple websites and start scanning for json results. I would eventually stumble upon the Associated Press site and would discover something that would solve most of my script issues.
I discovered that the AP site has a publicly exposed API that you can call. When you launch the AP news site and head to Top Stories, the web app sends a GET request to afs-prod.appspot.com. This returns a collection of JSON objects (the Associated Press refers to them as cards) that each represent a news article. Each card has a URN that is associated to a news article. When you click on a card, it sends another GET request to storage.googleapis.com with that URN, and returns with another JSON object that contains the news article with full text and metadata about the article.
This solved multiple issues. For one, this API call sent data in plain text, so all we have to do now is parse the JSON object (which is way easier than parsing HTML elements). This also ment that we don't need to deal with JavaScript since the returned data is just a plain text json response. We also don't have to worry about changes to JSON responses since APIs rarely (if ever) change and fixing an API change for JSON is way more simpler than changing an element lookup.
Around this time, I also started experimenting with looking up APIs from other news sources. Reuters was another news site that I was still scraping HTML from for the longest time since I could not find JSON request when you visit the Reuters news site. This is probably because Reuters pre generates the website on the backend rather than letting the frontend generate the UI. However, my luck changed when I made yet another interesting discovery.
Reuters website doesn’t use a publicly exposed API, but it's mobile application does. So, after sniffing packets on my android phone, I eventually found out where the reuters app was getting the news from (wireapi.reuters.com). The only major difference between AP and Reuters API calls are different terminology (instead of cards, Reuters calls them wireItems) and how the JSON object is structured. Otherwise, it's a simple algorithm.
Get top headlines JSON Object
for each headline in JSON Object{
Get news Article
Parse elements (Headline, authors, story, etc.)
}
Save rss feed
While this new script solved a lot of issues, and even boosted performance, it still had error catching issues, and still had to run every 30 minutes to update. Once again, I shelved this project until I could solve the other two issues.
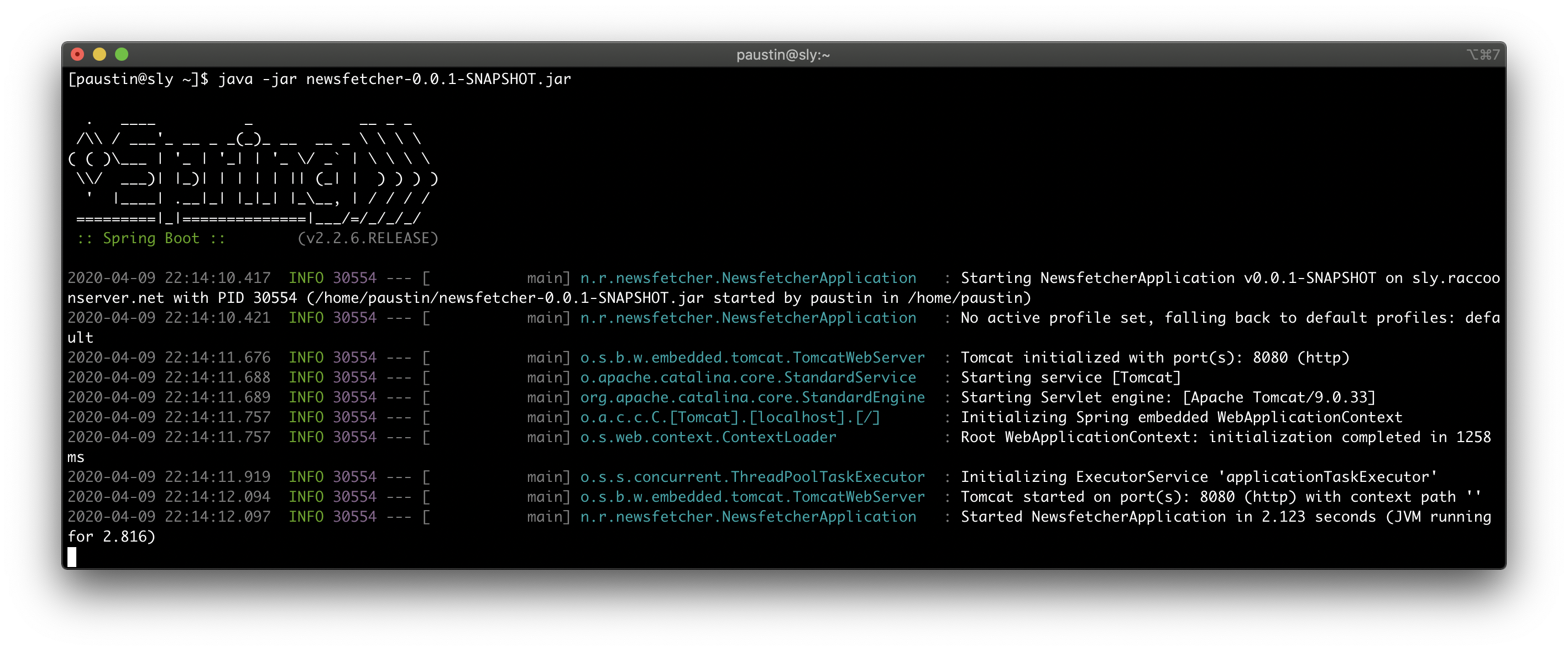
Recently, in preparation for a new position I'll be starting soon, I've been learning more about Spring Boot, and how you can generate your very own backend service. As a test to see how my learning was going, I decided to unshelve my news project to see if I can solve one of those issues. You see, if I turned this script into a backend RESTful call, then we don't need to run the script every 30 minutes, we only need to run it when we call the backend.
And so, in the span of an afternoon, I converted my old python script into a fully fledged Spring Boot application. By sending a GET request, the Spring Boot application can return an RSS feed that any rss feed reader can parse through. This solves the issue of having to run the script every 30 minutes, since we can generate the rss feed in a matter of seconds. This also allows me to implement better error handling since the Spring Boot application wont crash if it runs into an issue (it forces you to use exception capturing when making calls).
I still consider this project unfinished though, and lots of improvements still need to be made. For one, I'd like to go back and change the structure of the application. Since both news agencies pretty much use the same functions just with different url and different naming schemes, I would like to go back and reduce the number of repeated lines of code between the tow objects (since both the AP and Reuters classes have almost the exact same lines of code).
I would also like to figure out how to implement tokens, that way only I and maybe a few other can use these calls (and no one can spam these API calls). Finally, I would like to figure out how to dockerize this project so that deploying this project to my cloud environment can be easier.
I'll keep working on this project to fix those issues. In the meantime, you can check out my project here if you'd like to see how I did it.