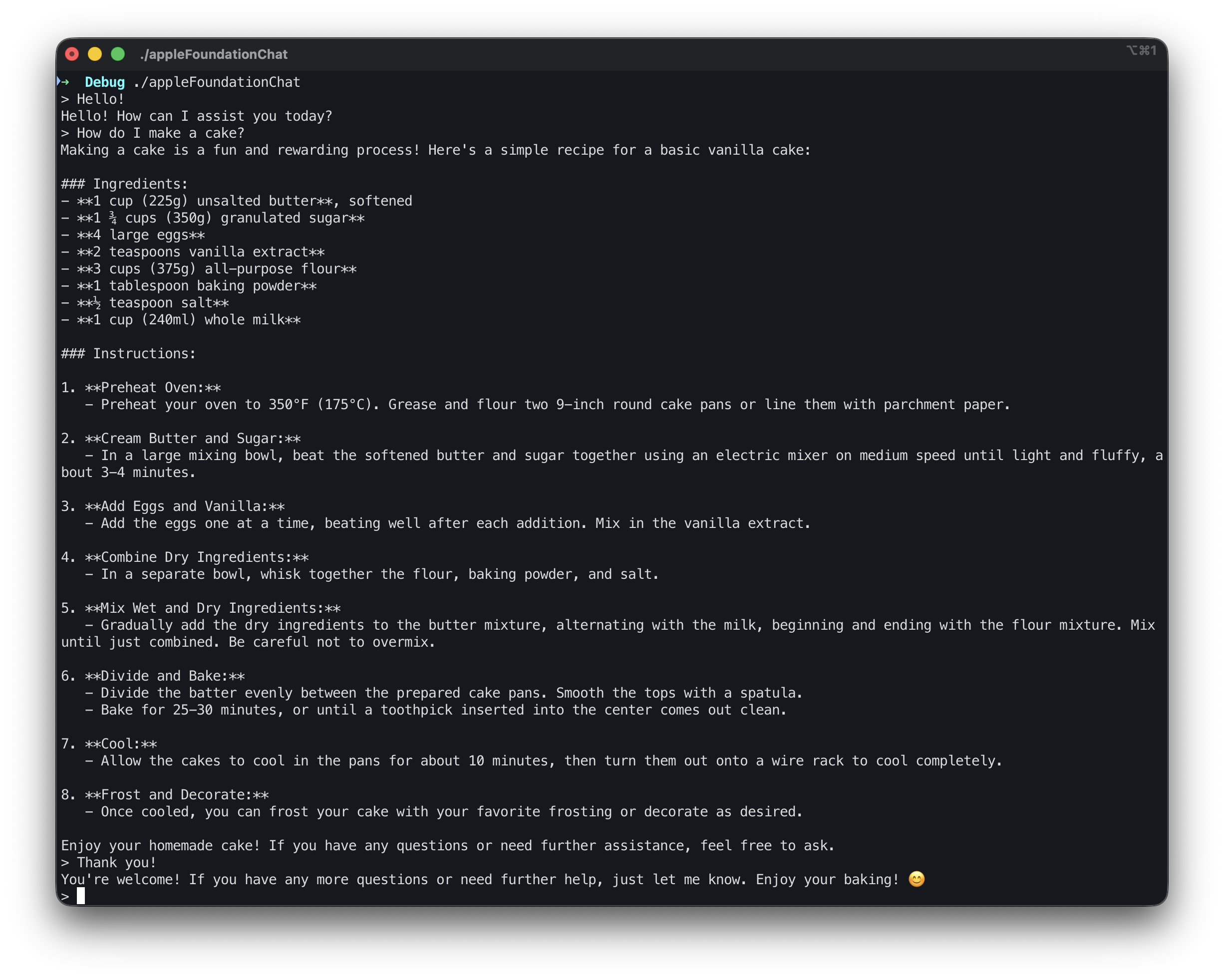
 For a while now, I've been wanting to make an AI chatbot that could run in my terminal. Utilizing some Large Language Model, I wanted to create a simple terminal program that could send request to a local (on device) LLM, and post the response in the terminal. But I wasn't entirely sure where to start.
For a while now, I've been wanting to make an AI chatbot that could run in my terminal. Utilizing some Large Language Model, I wanted to create a simple terminal program that could send request to a local (on device) LLM, and post the response in the terminal. But I wasn't entirely sure where to start.
That was, until I ran across this tweet, where user Adrien Grondin showed off an application that allows you to use Apple Intelligence's on device models (which Apple refers to as Foundation Models).
Unfortunately, it seems like the app is only available for iOS devices. The only Apple Intelligence device I own is my MacBook Pro, so I wouldn't be able to test out their iOS application. But it did get me thinking, if this is achievable in iOS, is it possible to use the same framework in a macOS application?
As it turns out, yes. Starting with macOS Tahoe you can now send direct request to Apple's on device LLM using the FoundationModels framework.
How to use FoundationModels
To get this to work, you will need
- A Mac with an eligible Apple Intelligence Chip (any Mac with an M-series chip)
- macOS Tahoe or Later
- Xcode 26 or later
- Apple Intelligence enabled in settings1
Here is the most basic method of sending a request to Apple's Foundation Models. You can run this code in Swift Playground2:
let session = LanguageModelSession()
do {
let response = try await session.respond(to: )
print(response.content)
} catch {
print()
}
By importing the FoundationModels framework, we can create a LanguageModelSession() and send a request to the session object. We get a text response back from the session object, and we can print the response to the terminal.
This is very impressive given just how little code we have to write.
We can further control how the LLM responds by giving it instructions:
let session = LanguageModelSession {
Instructions {
}
}
do {
let response = try await session.respond(to: )
print(response.content)
} catch {
print()
}
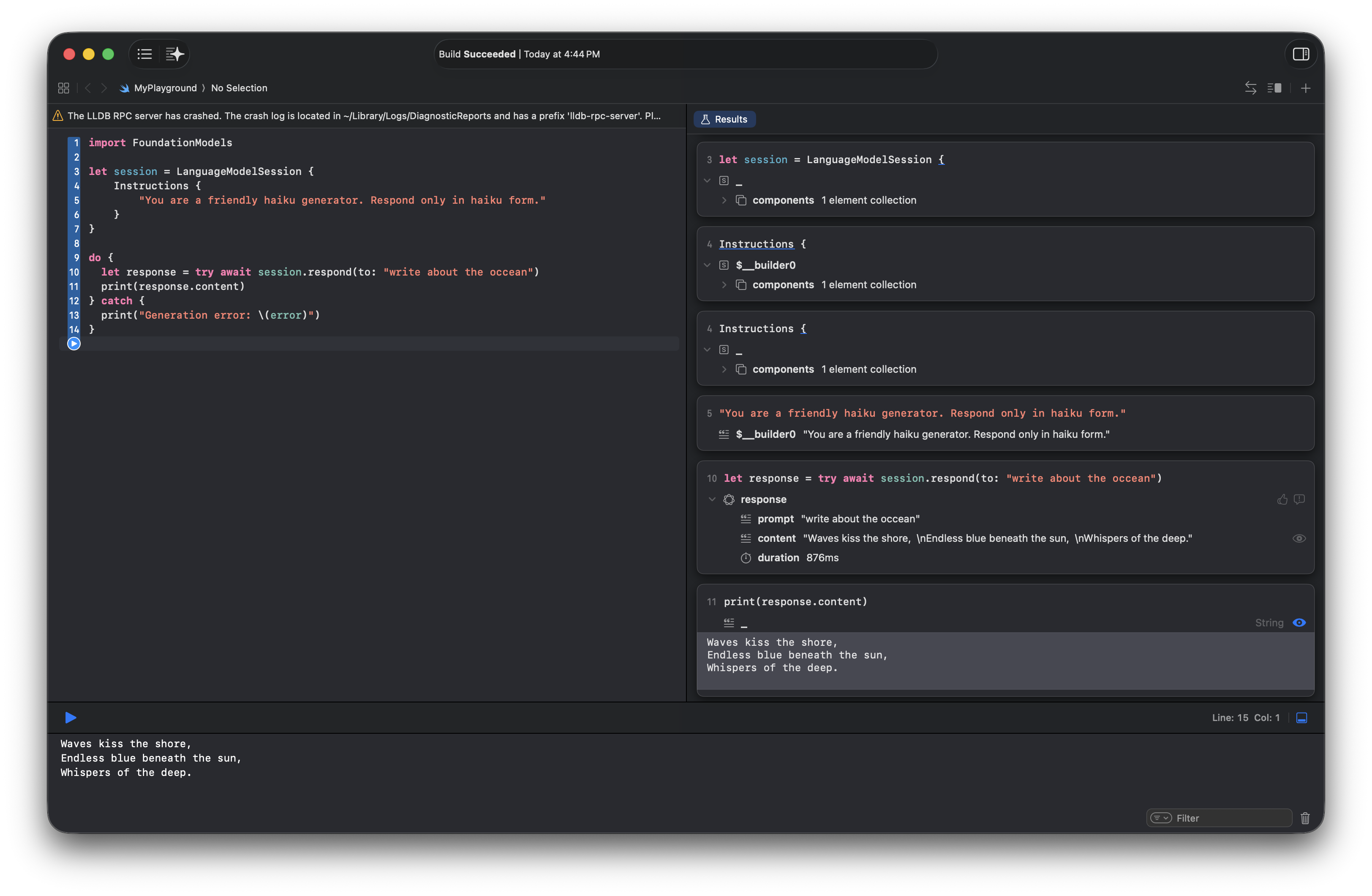 This is a good start, but we can do better. The reason we refer to
This is a good start, but we can do better. The reason we refer to LanguageModelSession() as a session is because we can keep sending responses to this LanguageModelSession(), and it will still maintain the context of the current session. In other words, we could write a program that allows us to keep chatting with the LanguageModelSession() similar to a standard AI chatbot service.
Why don't we do that? Let's do that:
let session = LanguageModelSession()
var userWantsToContinue: Bool = true
while(userWantsToContinue){
do {
print(, terminator: )
if let query = readLine(), !query.isEmpty {
if (query.lowercased() == || query.lowercased() == ){
userWantsToContinue = false
} else {
let response = try await session.respond(to: query)
print(response.content)
}
} else {
print()
}
} catch {
print()
}
}
Here we set a while loop that continues to loop while the boolean userWantsToContinue is true. We then print the grater than symbol to inform the user they can start typing. If they type quit or exit, it will set the boolean to false, and end the program. Otherwise, we then take the users query, and send it to the LanguageModelSession(), and print out the LLM's response. We then keep looping the program until the user is done "chatting" with the LLM.
So far so good, but we can do better! Most chatbots don't wait until it a response is fully available; they typically stream the output of it's progress to its user.
So let's do that:
let session = LanguageModelSession()
var userWantsToContinue: Bool = true
while(userWantsToContinue){
do {
print(, terminator: )
if let query = readLine(), !query.isEmpty {
if (query.lowercased() == || query.lowercased() == ){
userWantsToContinue = false
} else {
let response = session.streamResponse(to: query)
var printedCount = 0
for try await partialResponse in response {
let content = partialResponse.content
let delta = content.dropFirst(printedCount)
print(delta, terminator: )
printedCount = content.count
}
print()
}
} else {
print()
}
} catch {
print()
}
}
Here, we change the response into a streamResponse, this allows us to process the output as a continuous stream of text. We then loop through each iteration of the text generation. Each time we loop, we grab the current content of the stream (partialResponse). We then grab the delta (the newest characters from the stream) by taking the current content of the stream, removing the characters already posted in the terminal session (using the printedCount variable to keep track of how many characters we've posted so far), print the delta, and then set printedCount to the current length of the stream. Now the text will appear as the LLM is producing the final output.
Thoughts on Apple Intelligence
Prior to this discovery, I viewed Apple Intelligence as nothing more than a marketing gimmick. A simple trick to get their shareholders to stop asking about their AI strategy.
But now, I'm starting to see the real vision of what Apple is trying todo with AI. By focusing on on-device LLMs (rather than cloud based LLMs) Apple is giving its users (and developers) the ability to take advantage of local LLMs without needing to use third party LLM services. The simplicity of the framework is also very impressive; the amount of code required to use the LLMs is very minimal, and simple to understand. This will no doubt make developing AI tools on macOS and iOS very intuitive.
I'm looking forward to seeing what Apple can accomplish with Apple Intelligence in the future!
I'll be writing a bigger post on my thoughts on Artificial Intelligence in the near future, so please continue to follow my blog!
Some portions of this post was written with the assistance of Large Language Models (LLMs).